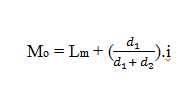Dispersi
atau variasi atau keragaman data adalah ukuran penyebaran suatu kelompok data
terhadap pusat data.
Jenis – jenis Ukuran Variasi (Dispersi)
a.
Range
Range
merupakan selisih antara nilai data terbesar dengan data terkecil dari
sekelompok data.
Rumusannya
adalah R = Nilai maksimal – Nilai minimal
b. Simpangan
rata-rata
Simpangan Rata-Rata (Sr) : Yang dimaksud dengan
simpangan (deviation) adalah selisih antara nilai pengamatan ke-I dengan nilai
rata-rata, atau antara xi dengan X (X Rata-Rata) Penjumlahan daripada
simpangan-simpangan dalam pengamatan kemudian dibagi dengan jumlah pengamatan,
n, disebut dengan simpangan rata-rata.
Dengan Rumus :

Data
dikelompokkan

C. Variansi
(variance)
Variansi (variance) adalah rata-rata kuadrat selisih
atau kuadrat simpangan dari semua nilai data terhadap rata-rata hitung. Varians
untuk sampel dilambangkan dengan S2. Sedangkan untuk populasi dilambangkan
dengan toh kuadrat .
Dengan Rumus :

Data
dikelompokkan
D.
Simpangan Baku
(Standard Deviation)
Standar deviasi
(standard deviation) adalah akar pangkat dua dari variansi. Standar deviasi
seringkali disebut sebagai simpangan baku.
Dengan Rumus :

E.
Jangkauan
Kuartil
Jangkauan Kuartil atau
simpangan kuartil adalah setengah dari selisih antara kuartil atas (Q3) dengan
kuartil bawah (Q1).
Dengan rumus :

F.
Jangkauan
Persentil
Jangkauan Persentil
adalah selisih antara persentil ke-90 dengan persentil ke-10.
Dengan rumus :
JP (10-90) =
P90-P1